1.kNN算法理论
1.什么是kNN算法?¶
KNN是英文k-nearest neighbor(K最近邻)的缩写。是一个基本的分类和回归的算法,它是属于监督学习中分类方法的一种。事实上,kNN可以说是最简单的机器学习算法。尽管kNN很简单,但它可以提供令人惊讶的良好分类性能,并且其简单性使其易于解释。。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。平常生活中我们都会下意识的运用到我们的判断中,比如富人区和穷人区,判断一个人是富人还是穷人根据他的朋友的判断,就是运用了kNN的思想。
我们可以用两个阶段来描述 kNN 算法(和其他机器学习算法):
- 训练阶段
- 预测阶段
kNN 算法的训练阶段仅包括存储数据。
在预测阶段,kNN 算法计算每个新的、未标记的事例与所有标记事例之间的距离。当我说“距离”时,我指的是它们在攻击性和体长变量方面的接近程度,而不是你在树林里发现它们有多远!这个距离度量通常被称为欧几里得距离,在二维甚至三维中很容易在你的脑海中可视化为图上两点之间的直线距离。这是在数据中存在的维度中计算的。
2.R语言实现¶
2.1 包的安装¶
# INSTALLING AND LOADING PACKAGES ----
install.packages("mlr", dependencies = TRUE) # could take several minutes
# only needed once on any R installation
library(mlr)
library(tidyverse)
2.2 案例数据¶
医院从糖尿病患者那里收集几个月的诊断数据,并记录他们是否被诊断为健康、化学糖尿病或显性糖尿病。这里使用 kNN 算法来训练一个模型,该模型可以预测新患者将属于哪些类别,以便改进诊断。这是一个三类分类问题。
现在,让我们加载一些内置到 mclust 包中的数据,将其转换为 tibble,并对其进行一些探索:
# LOADING DIABETES DATA ----
data(diabetes, package = "mclust")
diabetesTib <- as_tibble(diabetes)
summary(diabetesTib)
diabetesTib
MedBioInfoCloud: summary(diabetesTib)
class glucose insulin sspg
Chemical:36 Min. : 70 Min. : 45.0 Min. : 10.0
Normal :76 1st Qu.: 90 1st Qu.: 352.0 1st Qu.:118.0
Overt :33 Median : 97 Median : 403.0 Median :156.0
Mean :122 Mean : 540.8 Mean :186.1
3rd Qu.:112 3rd Qu.: 558.0 3rd Qu.:221.0
Max. :353 Max. :1568.0 Max. :748.0
MedBioInfoCloud:
MedBioInfoCloud: diabetesTib
# A tibble: 145 x 4
class glucose insulin sspg
<fct> <dbl> <dbl> <dbl>
1 Normal 80 356 124
2 Normal 97 289 117
3 Normal 105 319 143
4 Normal 90 356 199
5 Normal 90 323 240
6 Normal 86 381 157
7 Normal 100 350 221
8 Normal 85 301 186
9 Normal 97 379 142
10 Normal 97 296 131
# ... with 135 more rows
# i Use `print(n = ...)` to see more rows
MedBioInfoCloud:
该数据集包含 145 个案例和 4 个变量。其中76例为正常,36例为化学糖尿病,33例为显性糖尿病。其他三个变量是葡萄糖耐量试验后血糖和胰岛素水平的连续测量和稳态血糖水平。
简单探索变量之间的关系
# PLOT THE RELATIONSHIPS IN THE DATA ----
p1 <- ggplot(diabetesTib, aes(glucose, insulin, col = class)) +
geom_point() +
theme_bw()
p2 <- ggplot(diabetesTib, aes(sspg, insulin, col = class)) +
geom_point() +
theme_bw()
p3 <- ggplot(diabetesTib, aes(sspg, glucose, col = class)) +
geom_point() +
theme_bw()
library(Rmisc)
multiplot(p1,p2,p3, cols = 3)

我们将从构建 kNN 模型的简单、朴素的方式开始。
2.3 构建模型¶
我们试图解决的问题是将新患者分为三类之一,现在我们需要训练 kNN 算法来构建一个可以解决这个问题的模型。mlr 包构建机器学习模型有三个主要阶段:
- 定义任务:该任务由数据以及我们想要用它做什么组成。在这种情况下,数据是,我们希望使用变量作为目标变量对数据进行分类。diabetesTibclass
- 定义学习器:学习器只是我们计划使用的算法的名称,以及算法接受的任何其他参数。
- 训练模型:这个阶段听起来像:您将任务传递给学习者,学习者生成一个可用于进行未来预测的模型。

(1)定义任务¶
可以通过makeClassifTask()函数定义分类任务来构建分类模型。
makeClassifTask(
id = deparse(substitute(data)),
data,
target,
weights = NULL,
blocking = NULL,
coordinates = NULL,
positive = NA_character_,
fixup.data = "warn",
check.data = TRUE
)
-
id:默认值是传递给data的R变量的名称。
-
data:包含特征和目标变量的data.frame
-
target:目标变量的名称。对于生存分析,这些是生存时间和事件列的名称,因此其长度为2。对于多标签分类,它包含编码标签是否存在的逻辑列名称,其长度对应于类的数量。
-
weights:(numeric)在拟合过程中使用的可选非负大小写权重向量。无法为cost-sensitive learning设置。默认值为NULL,这意味着没有(等于)权重。
-
blocking:(factor)与观测次数长度相同的可选因子。具有相同blocking水平的观测结果“属于同一个”。具体来说,在重新采样迭代期间,它们要么全部放入训练集,要么放入测试集。默认值为NULL,表示没有blocking。
-
coordinates:(data.frame)空间数据集的坐标,将用于空间交叉验证重采样设置中数据的空间分区。坐标必须是数值。提供的data.fram需要具有与data相同的行数,并且至少包含两个维度。
-
positive:二进制分类的阳性类(否则忽略并设置为NA)。Default是目标属性的第一个因子级别。
-
fixup.data:是否应该进行一些基本的数据清理?目前,这意味着删除列的空因子级别。可能的选择是:“no”=不做。“warn”=做但要警告。“quiet”=做但保持沉默。默认值为“warn”。
-
check.data:逻辑值,是否应该在任务创建时首先检查数据的完整性?你应该有很好的理由关闭它(一个可能是速度)。默认为TRUE。
# DEFINING THE DIABETES TASK ----
diabetesTask <- makeClassifTask(data = diabetesTib, target = "class")
diabetesTask

(2)定义学习器¶
就是告诉mlr使用哪种算法??

我们使用的算法类别:
- "classif."用于分类
- "regr."用于回归
- "cluster."用于聚类
- "surv."以及预测生存和多标签分类
下面使用makeLearner()函数来定义学习器。makeLearner()第一个参数是用于训练模型的算法。par.vals参数代表参数值,它允许我们指定我们希望算法使用的 k 最近邻的数量。现在,我们只将其设置为 2,后面会讨论如何选择k:
# DEFINING THE KNN LEARNER ----
knn <- makeLearner("classif.knn", par.vals = list("k" = 2))
mlr包有大量的机器学习算法,可以将这些算法提供给makeLearner()函数。
# LISTING ALL OF MLR'S LEARNERS ----
listLearners()$class
[1] "classif.ada" "classif.adaboostm1"
[3] "classif.bartMachine" "classif.binomial"
[5] "classif.boosting" "classif.bst"
[7] "classif.C50" "classif.cforest"
[9] "classif.clusterSVM" "classif.ctree"
[11] "classif.cvglmnet" "classif.dbnDNN"
[13] "classif.dcSVM" "classif.earth"
[15] "classif.evtree" "classif.fdausc.glm"
[17] "classif.fdausc.kernel" "classif.fdausc.knn"
[19] "classif.fdausc.np" "classif.FDboost"
[21] "classif.featureless" "classif.fgam"
[23] "classif.fnn" "classif.gamboost"
[25] "classif.gaterSVM" "classif.gausspr"
[27] "classif.gbm" "classif.glmboost"
[29] "classif.glmnet" "classif.h2o.deeplearning"
[31] "classif.h2o.gbm" "classif.h2o.glm"
[33] "classif.h2o.randomForest" "classif.IBk"
[35] "classif.J48" "classif.JRip"
[37] "classif.kknn" "classif.knn"
[39] "classif.ksvm" "classif.lda"
[41] "classif.LiblineaRL1L2SVC" "classif.LiblineaRL1LogReg"
[43] "classif.LiblineaRL2L1SVC" "classif.LiblineaRL2LogReg"
[45] "classif.LiblineaRL2SVC" "classif.LiblineaRMultiClassSVC"
[47] "classif.logreg" "classif.lssvm"
[49] "classif.lvq1" "classif.mda"
[51] "classif.mlp" "classif.multinom"
[53] "classif.naiveBayes" "classif.neuralnet"
[55] "classif.nnet" "classif.nnTrain"
[57] "classif.OneR" "classif.pamr"
[59] "classif.PART" "classif.penalized"
[61] "classif.plr" "classif.plsdaCaret"
[63] "classif.probit" "classif.qda"
[65] "classif.randomForest" "classif.ranger"
[67] "classif.rda" "classif.rFerns"
[69] "classif.rotationForest" "classif.rpart"
[71] "classif.RRF" "classif.saeDNN"
[73] "classif.sda" "classif.sparseLDA"
[75] "classif.svm" "classif.xgboost"
[77] "cluster.cmeans" "cluster.Cobweb"
[79] "cluster.dbscan" "cluster.EM"
[81] "cluster.FarthestFirst" "cluster.kkmeans"
[83] "cluster.kmeans" "cluster.MiniBatchKmeans"
[85] "cluster.SimpleKMeans" "cluster.XMeans"
[87] "multilabel.cforest" "multilabel.rFerns"
[89] "regr.bartMachine" "regr.bcart"
[91] "regr.bgp" "regr.bgpllm"
[93] "regr.blm" "regr.brnn"
[95] "regr.bst" "regr.btgp"
[97] "regr.btgpllm" "regr.btlm"
[99] "regr.cforest" "regr.crs"
[101] "regr.ctree" "regr.cubist"
[103] "regr.cvglmnet" "regr.earth"
[105] "regr.evtree" "regr.FDboost"
[107] "regr.featureless" "regr.fgam"
[109] "regr.fnn" "regr.frbs"
[111] "regr.gamboost" "regr.gausspr"
[113] "regr.gbm" "regr.glm"
[115] "regr.glmboost" "regr.glmnet"
[117] "regr.GPfit" "regr.h2o.deeplearning"
[119] "regr.h2o.gbm" "regr.h2o.glm"
[121] "regr.h2o.randomForest" "regr.IBk"
[123] "regr.kknn" "regr.km"
[125] "regr.ksvm" "regr.laGP"
[127] "regr.LiblineaRL2L1SVR" "regr.LiblineaRL2L2SVR"
[129] "regr.lm" "regr.mars"
[131] "regr.mob" "regr.nnet"
[133] "regr.pcr" "regr.penalized"
[135] "regr.plsr" "regr.randomForest"
[137] "regr.ranger" "regr.rpart"
[139] "regr.RRF" "regr.rsm"
[141] "regr.rvm" "regr.svm"
[143] "regr.xgboost" "surv.cforest"
[145] "surv.coxph" "surv.cvglmnet"
[147] "surv.gamboost" "surv.gbm"
[149] "surv.glmboost" "surv.glmnet"
[151] "surv.ranger" "surv.rpart"
可以按功能列出:
# or list them by function:
listLearners("classif")$class
listLearners("regr")$class
listLearners("cluster")$class
(3)训练模型¶
训练模型所需的组件是我们之前定义的学习器和任务。定义任务和学习器并将它们组合以训练模型的整个过程:

这是通过train()函数实现的,该函数将学习器作为第一个参数,将任务作为其第二个参数。
# DEFINE MODEL ----
knnModel <- train(knn, diabetesTask)
建好的模型后,所以让数据传递给模型,并观察如何执行。predict()函数的作用是获取未标记的数据,并将其传递到模型中以获取预测的类。predict()函数第一个参数是模型,想要传递给模型的数据可作为newdata参数给出。
# TESTING PERFORMANCE ON TRAINING DATA (VERY BAD PRACTICE) ----
knnPred <- predict(knnModel, newdata = diabetesTib)
我们可以将这些预测作为performance()函数的第一个参数传递。此函数将模型预测的类与 true 类进行比较,并返回预测值和 true 值相互匹配程度的性能指标。

我们通过将它们作为列表提供给参数来指定我们希望函数返回的性能指标。我要求的两个度量是平均误分类误差(MMCE)和或准确率(acc)。MMCE表示模型错分样本的比例。准确性与MMCE相反,acc表示模型正确分类样本的比例。两者的总和为 1.00。
performance(knnPred, measures = list(mmce, acc))
MedBioInfoCloud: performance(knnPred, measures = list(mmce, acc))
mmce acc
0.06206897 0.93793103
我们的模型正确分类了 93.8% 的案例!这是否意味着它将在未来患者中表现出良好的预测?事实是我们不知道。通过要求模型对你最初用于训练它的数据进行预测来评估模型性能,这几乎不会告诉你模型在对完全看不见的数据进行预测时将如何执行。因此,切勿以这种方式评估模型性能。在我们讨论原因之前,我想介绍一个重要的概念,称为偏差-方差权衡。
(4)偏差-方差权衡¶
欠拟合和过拟合是模型构建中误差的两个重要来源。在欠拟合中,我们包含的预测因子太少或模型太简单,无法充分描述数据中的关系/模式。结果是一个据说有偏差的模型:一个在我们用来训练它的数据和新数据上表现不佳的模型。
过度拟合与欠拟合相反,它描述了我们包含太多预测因子或太复杂的模型的情况,这样我们不仅要对数据中的关系/模式进行建模,还要对噪声进行建模。数据集中的噪声是与我们测量的变量没有系统相关性的变化,而是由于变量测量的固有变异性和/或误差造成的。噪声模式非常特定于单个数据集,因此如果我们开始对噪声进行建模,我们的模型可能会在我们训练它的数据上表现非常好,但对于未来的数据集给出的结果却有很大差异。
泛化误差是模型做出的错误预测的比例,是过度拟合和欠拟合的结果。与过度拟合(模型过于复杂)相关的误差是方差。与欠拟合(模型太简单)相关的误差是偏差。与过度拟合(模型过于复杂)相关的误差是方差。最佳模型可以平衡这种权衡。欠拟合和过度拟合都会引入误差并降低模型的泛化性:模型泛化到未来看不见的数据的能力。它们也是相互对立的:介于欠拟合和有偏差的模型和过度拟合和有方差的模型之间,是平衡偏差-方差权衡的最佳模型。

两类分类问题的欠拟合、最优拟合和过拟合示例。虚线表示决策边界。

(5)交叉验证¶
我们使用一部分数据来训练模型:这部分称为训练集。我们使用算法在训练期间从未看到的其余部分来测试模型:这部分是测试集。然后,我们评估模型在测试集上的预测与其真实值的接近程度。衡量训练好的模型在测试集上的表现如何有助于我们确定我们的模型在看不见的数据上是否表现良好,或者我们是否需要进一步改进它。
此过程称为交叉验证 (CV),它是任何监督式机器学习管道中极其重要的方法。一旦我们交叉验证了我们的模型并对其性能感到满意,我们就使用我们拥有的所有数据(包括测试集中的数据)来训练最终模型(因为通常,我们训练模型的数据越多,它的偏差就越小)。
有三种常见的交叉验证方法:
- 留出法交叉验证
- K -折法交叉验证
- 留一法交叉验证
留出法交叉验证¶
数据随机分为训练集和测试集。训练集用于训练模型,然后用于对测试集进行预测。预测与测试集真实值的相似性用于评估模型性能。
在 MLR 中使用任何交叉验证的第一步是进行重采样描述,这只是一组关于如何将数据拆分为测试和训练集的说明。makeResampleDesc()函数的第一个参数是我们将要使用的交叉验证方法。在本例中,留出法(Holdout)交叉验证 ,我们需要告诉函数中有多少比例的数据将用作训练集,因此我们将其提供给split参数。另外,还有一个额外的可选参数stratify = TRUE。它要求函数确保在将数据拆分为训练集和测试集时,它会尝试保持每组每类患者的比例。
# PERFORMING HOLD-OUT CROSS-VALIDATION ----
holdout <- makeResampleDesc(method = "Holdout", split = 2/3,
stratify = TRUE)
定义好如何交叉验证我们的学习器之后,我们可以使用resample()函数进行交叉验证了。resample()函数提供了创建学习器和任务以及刚才定义的重采样方法。
holdoutCV <- resample(learner = knn, task = diabetesTask,
resampling = holdout,
measures = list(mmce, acc))
resample()函数在运行时输出性能度量,这些度量可以通过从resampling对象中提取$aggr组建得到。
MedBioInfoCloud: holdoutCV$aggr
mmce.test.mean acc.test.mean
0.06122449 0.93877551
为了更好地了解哪些组被正确分类,哪些被错误分类,我们可以构建一个混淆矩阵。混淆矩阵只是测试集中每个事例的真实和预测类的表格表示。使用 mlr包种的calculateConfusionMatrix()函数计算混淆矩阵。第一个参数是 holdoutCV对象的pred组件,它包含测试集的真实类和预测类。可选参数relative要求函数显示每个类在真实和预测类标签中的比例。
calculateConfusionMatrix(holdoutCV$pred, relative = TRUE)

绝对混淆矩阵更容易解释。行显示真实的类标签,列显示预测的标签。这些数字表示真实类和预测类的每种组合中的样本数。例如,在这个矩阵中,10名患者被正确归类为化学糖尿病,但一名患者被错误地归类为健康,一名患者被错误地归类为显性糖尿病。正确分类的患者位于矩阵的对角线上(其中真实类==预测类)。
K -折法交叉验证¶
在K -折法交叉验证中,我们将数据随机拆分为大约相等大小的子集。然后,我们将其中一个子集保留为测试集,并使用剩余的数据作为训练集(留出法交叉验证一样)。我们通过模型通过测试集,并记录相关的性能指标。在此过程中,数据中的每个样本仅在测试集中出现一次。

这种方法通常会对模型性能进行更准确的估计,因为每个事例在测试集中出现一次,并且我们正在对多次运行的估计值求平均值。但是我们可以通过使用重复的 k-fold 交叉验证 来稍微改善这一点,在上一个过程之后,我们将数据打乱并再次执行。
例如,对于 k 折法,通常选择的k值是 10。同样,这取决于数据的大小等,但对于许多数据集来说,这是一个合理的值。这意味着我们将数据分成 10 个大小几乎相等的块并执行交叉验证。如果我们重复此过程 5 次,那么我们有 10 倍的交叉验证重复 5 次(这与 50 倍的 交叉验证不同),模型性能的估计将是 50 次不同运行的平均值。
因此,如果有计算资源,通常最好使用重复的K -折法交叉验证而不是普通的K -折法交叉验证。
我们执行 K -折法交叉验 的方式与留出法相同。这一次,函数将使用重复的K -折法交叉验证来进行重采样描述,并告诉它我们要将数据拆分为多少个子集。默认k为 10,这通常是一个不错的选择,但我想向您展示如何显式控制拆分。接下来,使用函数参数reps参数重复进行50次的10-折交叉验证。这将提供了 500 次试验来平均性能度量!同样,这里要求在子集中对类别进行分层采样。
# PERFORMING REPEATED K-FOLD CROSS-VALIDATION ----
kFold <- makeResampleDesc(method = "RepCV", folds = 10, reps = 50,
stratify = TRUE)
kFoldCV <- resample(learner = knn, task = diabetesTask,
resampling = kFold, measures = list(mmce, acc))
提取平均性能度量:
MedBioInfoCloud: kFoldCV$aggr
mmce.test.mean acc.test.mean
0.1045667 0.8954333
我们通常只对平均性能度量感兴趣,但您可以通过运行 来访问每次迭代的性能度量。
kFoldCV$measures.test
交叉验证模型时的目标是尽可能准确和稳定地估计模型性能。从广义上讲,您可以做的重复次数越多,这些估计就会变得越准确和稳定。但是,在某些时候,重复次数越多,性能估算的准确性或稳定性也不会提高。
那么,您如何决定要执行多少次重复呢?一种合理的方法是选择计算合理的重复次数,运行该过程几次,然后查看平均性能估计值是否变化很大。如果没有,那就太好了。如果它确实变化很大,您应该增加重复次数。
计算混淆矩阵:
calculateConfusionMatrix(kFoldCV$pred, relative = TRUE)
MedBioInfoCloud: calculateConfusionMatrix(kFoldCV$pred, relative = TRUE)
Relative confusion matrix (normalized by row/column):
predicted
true Chemical Normal Overt -err.-
Chemical 0.81/0.79 0.09/0.04 0.09/0.11 0.19
Normal 0.04/0.07 0.96/0.96 0.00/0.00 0.04
Overt 0.16/0.14 0.00/0.00 0.84/0.89 0.16
-err.- 0.21 0.04 0.11 0.10
Absolute confusion matrix:
predicted
true Chemical Normal Overt -err.-
Chemical 1464 169 167 336
Normal 135 3665 0 135
Overt 260 0 1390 260
-err.- 395 169 167 731
留一法交叉验证¶
留一法交叉验证可以被认为是 K -折法交叉验证 的极端:我们不是将数据分解成折叠,而是保留单个观察作为测试用例,在其余数据的整体上训练模型,然后通过测试用例传递它并记录相关的性能指标。接下来,我们做同样的事情,但选择不同的观察作为测试用例。我们继续这样做,直到每个观察都被用作测试用例一次,我们取性能指标的平均值。

由于测试集只是一个观测值,因此留一法交叉验证倾向于给出模型性能的相当可变的估计值(因为每次迭代的性能估计值取决于正确标记该单个测试用例)。但是,当您的数据集较小时,它可以提供比 k 折法更少的模型性能估计值。当你有一个小数据集时,将其拆分成k个折叠将给你留下一个非常小的训练集。在小型数据集上训练的模型的方差往往更高,因为它会受到采样错误/异常情况的影响更大。因此,留一法交叉验证对于将其拆分为k个折叠会给出可变结果的小型数据集很有用。它在计算上也比重复的 k 折法交叉成本低。
未经交叉验证的监督学习模型实际上是无用的,因为您不知道它对新数据所做的预测是否准确。
进行重采样描述,方法LOO,因为测试集只是一个案例,所以不能对留一法交叉验证进行分层采样。此外,由于每个事例用作测试集一次,所有其他数据用作训练集,因此无需重复该过程。
# PERFORMING LEAVE-ONE-OUT CROSS-VALIDATION ----
LOO <- makeResampleDesc(method = "LOO")
执行交叉验证,得到平均性能的测量值。
LOOCV <- resample(learner = knn, task = diabetesTask, resampling = LOO,
measures = list(mmce, acc))
LOOCV$aggr
MedBioInfoCloud: LOOCV$aggr
mmce.test.mean acc.test.mean
0.07586207 0.92413793
计算混淆矩阵
calculateConfusionMatrix(LOOCV$pred, relative = TRUE)
MedBioInfoCloud: calculateConfusionMatrix(LOOCV$pred, relative = TRUE)
Relative confusion matrix (normalized by row/column):
predicted
true Chemical Normal Overt -err.-
Chemical 0.92/0.80 0.08/0.04 0.00/0.00 0.08
Normal 0.04/0.07 0.96/0.96 0.00/0.00 0.04
Overt 0.15/0.12 0.00/0.00 0.85/1.00 0.15
-err.- 0.20 0.04 0.00 0.08
Absolute confusion matrix:
predicted
true Chemical Normal Overt -err.-
Chemical 33 3 0 3
Normal 3 73 0 3
Overt 5 0 28 5
-err.- 8 3 0 11
2.4 如何选择k?¶
机器学习模型通常具有与之关联的参数。参数是根据数据估计得到的变量或值,位于模型内部,用于控制它如何对新数据进行预测。模型参数的一个示例是回归线的斜率。
在 kNN 算法中,k 不是一个参数,因为算法不会从数据中估计它(事实上,kNN 算法实际上并没有学习任何参数)。相反,k 是所谓的超参数:控制模型预测的变量或选项,但超参数不是通过对数据进行估计获得的。我们不必为模型提供参数,我们只是提供数据,算法自己学习参数。但是,我们确实需要提供算法学习时所需的任何超参数。不同的算法需要并使用不同的超参数来控制它们如何学习模型。
k是kNN算法的一个超参数,所以算法本身无法估计,由我们来选择一个值。我们如何决定?
有三种方法可以选择 k 或其他任何超参数:
- 选择一个以前处理过类似问题的“合理的”值或默认值。 此选项是个坏主意。你无法知道你选择的k的值是否是最好的。仅仅因为某个值在其他数据集上起作用并不意味着它会在此数据集上表现良好。
- 手动尝试几个不同的值,看看哪一个能提供最佳性能。此选项更好一些。这里的想法是,你选择几个合理的k值,用它们中的每一个构建一个模型,看看哪个模型表现最好。这样更好,因为您更有可能找到表现最佳的 k 值;但是您仍然不能保证找到它,并且手动执行此操作可能既乏味又缓慢。这是数据科学家的选择,他们关心但并不真正知道他们在做什么。
- 使用称为超参数优化的过程自动执行选择过程。 这个解决方案是最好的。它最大限度地提高了您找到 k 的最佳性能值的可能性,同时还为您自动化了该过程。
(1)调整 k 以改进模型¶
我们需要做的第一件事是定义一个值范围,在调整 k 时,mlr 将尝试这些值:
# HYPERPARAMETER TUNING OF K ----
knnParamSpace <- makeParamSet(makeDiscreteParam("k", values = 1:10))
接下来,定义 mlr 搜索参数空间的方式,可供选择的方法有几种,这里使用网格搜索方法。这可能是最简单的方法:在查找性能最佳的值时,它会尝试参数空间中的每个值。对于调整连续超参数,或者当我们一次调整多个超参数时,网格搜索计算代价大。可以选择其他方法,比如随机搜索法。
gridSearch <- makeTuneControlGrid()
接下来,定义如何交叉验证调优过程。这里使用k-折法交叉验证
cvForTuning <- makeResampleDesc("RepCV", folds = 10, reps = 20)
调用函数来执行调优:
tunedK <- tuneParams("classif.knn", task = diabetesTask,
resampling = cvForTuning,
par.set = knnParamSpace,
control = gridSearch)
第一个和第二个参数分别是我们应用的算法和任务的名称。我们将 交叉验证策略作为参数resampling,将超参数空间定义为par.set参数,并将搜索过程提供给control参数。
以通过选择组件直接访问 k 的最佳性能值。
tunedK
tunedK$x
MedBioInfoCloud: tunedK
Tune result:
Op. pars: k=7
mmce.test.mean=0.0799524
MedBioInfoCloud: tunedK$x
$k
[1] 7
可视化选择。
knnTuningData <- generateHyperParsEffectData(tunedK)
plotHyperParsEffect(knnTuningData, x = "k", y = "mmce.test.mean",
plot.type = "line") +
theme_bw()

现在使用最优的 k训练最终模型:
# TRAINING FINAL MODEL WITH TUNED K ----
tunedKnn <- setHyperPars(makeLearner("classif.knn"), par.vals = tunedK$x)
tunedKnnModel <- train(tunedKnn, diabetesTask)
(2)在交叉验证中调整超参数¶
现在,当我们对数据或模型执行某种预处理时,例如调整超参数,重要的是将此预处理包含在我们的交叉验证中,以便我们交叉验证整个模型训练过程。这采用嵌套交叉验证 的形式,其中内部循环交叉验证超参数的不同值(就像我们之前所做的那样),然后将获胜的超参数值传递给外部交叉验证循环。在外部交叉验证循环中,获胜的超参数用于每个折叠。
嵌套式交叉验证是这样进行的:
-
将数据拆分为训练集和测试集(这可以使用留出法、k 折法或留一法)。这种划分称为外循环。
-
训练集用于交叉验证超参数搜索空间的每个值(使用我们决定的任何方法)。这称为内部循环。
-
从每个内部循环提供最佳交叉验证性能的超参数将传递到外部循环。
-
模型在外循环的每个训练集上使用其内循环中的最佳超参数进行训练。这些模型用于对其测试集进行预测。
-
然后,这些模型在外部循环中的平均性能指标将报告为模型在未见过的数据上的表现的估计值。

# INCLUDING HYPERPARAMETER TUNING INSIDE NESTED CROSS-VALIDATION ----
inner <- makeResampleDesc("CV")
outer <- makeResampleDesc("RepCV", folds = 10, reps = 5)
knnWrapper <- makeTuneWrapper("classif.knn", resampling = inner,
par.set = knnParamSpace,
control = gridSearch)
cvWithTuning <- resample(knnWrapper, diabetesTask, resampling = outer)
2.5 使用模型进行预测¶
我们可以自由地使用它来对新患者进行分类!让我们想象一下,一些新患者来到诊所:
# USING THE MODEL TO MAKE PREDICTIONS ----
newDiabetesPatients <- tibble(glucose = c(82, 108, 300),
insulin = c(361, 288, 1052),
sspg = c(200, 186, 135))
newDiabetesPatients
newPatientsPred <- predict(tunedKnnModel, newdata = newDiabetesPatients)
getPredictionResponse(newPatientsPred)
3.Python实现¶
3.1 查看鸢尾花iris数据集¶
#对鸢尾花iris数据集进行调用,查看数据的各方面特征。
from sklearn.datasets import load_iris
iris_dataset = load_iris()
#下面是查看数据的各项属性
print("数据集的Keys:\n",iris_dataset.keys()) #查看数据集的keys。
print("特征名:\n",iris_dataset['feature_names']) #查看数据集的特征名称
print("数据类型:\n",type(iris_dataset['data'])) #查看数据类型
print("数据维度:\n",iris_dataset['data'].shape) #查看数据的结构
print("前五条数据:\n{}".format(iris_dataset['data'][:5])) #查看前5条数据
#查看分类信息
print("标记名:\n",iris_dataset['target_names'])
print("标记类型:\n",type(iris_dataset['target']))
print("标记维度:\n",iris_dataset['target'].shape)
print("标记值:\n",iris_dataset['target'])
#查看数据集的简介
print('数据集简介:\n',iris_dataset['DESCR'][:20] + "\n.......") #数据集简介前20个字符
数据集的Keys:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
特征名:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
数据类型:
<class 'numpy.ndarray'>
数据维度:
(150, 4)
前五条数据:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
标记名:
['setosa' 'versicolor' 'virginica']
标记类型:
<class 'numpy.ndarray'>
标记维度:
(150,)
标记值:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
数据集简介:
.. _iris_dataset:
I
.......
#对iris数据集进行拆分,并查看拆分结果。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris_dataset = load_iris()
X_train, X_test, y_train, y_test = train_test_split( iris_dataset['data'], iris_dataset['target'], random_state=2)
print("X_train",X_train)
print("y_train",y_train)
print("X_test",X_test)
print("y_test",y_test)
print("X_train shape: {}".format(X_train.shape))
print("X_test shape: {}".format(X_test.shape))
X_train [[5.5 2.3 4. 1.3]
[6.9 3.1 5.1 2.3]
[6. 2.9 4.5 1.5]
[6.2 2.9 4.3 1.3]
[6.8 3.2 5.9 2.3]
[5. 2.3 3.3 1. ]
[4.8 3.4 1.6 0.2]
[6.1 2.6 5.6 1.4]
[5.2 3.4 1.4 0.2]
[6.7 3.1 4.4 1.4]
[5.1 3.5 1.4 0.2]
[5.2 3.5 1.5 0.2]
[5.5 3.5 1.3 0.2]
[4.9 2.5 4.5 1.7]
[6.2 3.4 5.4 2.3]
[7.9 3.8 6.4 2. ]
[5.4 3.4 1.7 0.2]
[6.7 3.1 5.6 2.4]
[6.3 3.4 5.6 2.4]
[7.6 3. 6.6 2.1]
[6. 2.2 5. 1.5]
[4.3 3. 1.1 0.1]
[4.8 3.1 1.6 0.2]
[5.8 2.7 5.1 1.9]
[5.7 2.8 4.1 1.3]
[5.2 2.7 3.9 1.4]
[7.7 3. 6.1 2.3]
[6.3 2.7 4.9 1.8]
[6.1 2.8 4. 1.3]
[5.1 3.7 1.5 0.4]
[5.7 2.8 4.5 1.3]
[5.4 3.9 1.3 0.4]
[5.8 2.8 5.1 2.4]
[5.8 2.6 4. 1.2]
[5.1 2.5 3. 1.1]
[5.7 3.8 1.7 0.3]
[5.5 2.4 3.7 1. ]
[5.9 3. 4.2 1.5]
[6.7 3.1 4.7 1.5]
[7.7 2.8 6.7 2. ]
[4.9 3. 1.4 0.2]
[6.3 3.3 4.7 1.6]
[5.1 3.8 1.5 0.3]
[5.8 2.7 3.9 1.2]
[6.9 3.2 5.7 2.3]
[4.9 3.1 1.5 0.1]
[5. 2. 3.5 1. ]
[4.9 3.1 1.5 0.1]
[5. 3.5 1.3 0.3]
[5.4 3.7 1.5 0.2]
[6.8 3. 5.5 2.1]
[6.3 3.3 6. 2.5]
[5. 3.4 1.6 0.4]
[5.2 4.1 1.5 0.1]
[6.3 2.5 5. 1.9]
[7.7 2.6 6.9 2.3]
[6. 2.2 4. 1. ]
[7.2 3.6 6.1 2.5]
[4.9 2.4 3.3 1. ]
[6.1 2.8 4.7 1.2]
[6.5 3. 5.2 2. ]
[5.1 3.5 1.4 0.3]
[7.4 2.8 6.1 1.9]
[5.9 3. 5.1 1.8]
[6.4 2.7 5.3 1.9]
[4.4 2.9 1.4 0.2]
[5.6 2.8 4.9 2. ]
[5.1 3.4 1.5 0.2]
[5. 3.3 1.4 0.2]
[5.7 2.6 3.5 1. ]
[6.9 3.1 5.4 2.1]
[5.5 2.6 4.4 1.2]
[6.3 2.8 5.1 1.5]
[7. 3.2 4.7 1.4]
[6.8 2.8 4.8 1.4]
[6.5 3.2 5.1 2. ]
[6.9 3.1 4.9 1.5]
[5.5 2.4 3.8 1.1]
[5.6 3. 4.5 1.5]
[6. 3. 4.8 1.8]
[6. 2.7 5.1 1.6]
[5.8 2.7 5.1 1.9]
[5.9 3.2 4.8 1.8]
[5.1 3.8 1.6 0.2]
[6.2 2.2 4.5 1.5]
[5.6 3. 4.1 1.3]
[5.6 2.5 3.9 1.1]
[5.8 2.7 4.1 1. ]
[6.4 3.1 5.5 1.8]
[6.6 2.9 4.6 1.3]
[5.5 4.2 1.4 0.2]
[4.4 3. 1.3 0.2]
[6.3 2.9 5.6 1.8]
[6.4 3.2 4.5 1.5]
[7.3 2.9 6.3 1.8]
[5. 3.6 1.4 0.2]
[7.1 3. 5.9 2.1]
[4.9 3.1 1.5 0.1]
[6.5 3. 5.5 1.8]
[6.7 3.3 5.7 2.1]
[5.4 3.4 1.5 0.4]
[6.1 2.9 4.7 1.4]
[4.6 3.2 1.4 0.2]
[6.7 3. 5.2 2.3]
[5.7 3. 4.2 1.2]
[5. 3.4 1.5 0.2]
[6.5 3. 5.8 2.2]
[6.6 3. 4.4 1.4]
[5. 3.5 1.6 0.6]
[4.6 3.6 1. 0.2]
[6.3 2.5 4.9 1.5]
[5.7 4.4 1.5 0.4]]
y_train [1 2 1 1 2 1 0 2 0 1 0 0 0 2 2 2 0 2 2 2 2 0 0 2 1 1 2 2 1 0 1 0 2 1 1 0 1
1 1 2 0 1 0 1 2 0 1 0 0 0 2 2 0 0 2 2 1 2 1 1 2 0 2 2 2 0 2 0 0 1 2 1 2 1
1 2 1 1 1 2 1 2 1 0 1 1 1 1 2 1 0 0 2 1 2 0 2 0 2 2 0 1 0 2 1 0 2 1 0 0 1
0]
X_test [[4.6 3.4 1.4 0.3]
[4.6 3.1 1.5 0.2]
[5.7 2.5 5. 2. ]
[4.8 3. 1.4 0.1]
[4.8 3.4 1.9 0.2]
[7.2 3. 5.8 1.6]
[5. 3. 1.6 0.2]
[6.7 2.5 5.8 1.8]
[6.4 2.8 5.6 2.1]
[4.8 3. 1.4 0.3]
[5.3 3.7 1.5 0.2]
[4.4 3.2 1.3 0.2]
[5. 3.2 1.2 0.2]
[5.4 3.9 1.7 0.4]
[6. 3.4 4.5 1.6]
[6.5 2.8 4.6 1.5]
[4.5 2.3 1.3 0.3]
[5.7 2.9 4.2 1.3]
[6.7 3.3 5.7 2.5]
[5.5 2.5 4. 1.3]
[6.7 3. 5. 1.7]
[6.4 2.9 4.3 1.3]
[6.4 3.2 5.3 2.3]
[5.6 2.7 4.2 1.3]
[6.3 2.3 4.4 1.3]
[4.7 3.2 1.6 0.2]
[4.7 3.2 1.3 0.2]
[6.1 3. 4.9 1.8]
[5.1 3.8 1.9 0.4]
[7.2 3.2 6. 1.8]
[6.2 2.8 4.8 1.8]
[5.1 3.3 1.7 0.5]
[5.6 2.9 3.6 1.3]
[7.7 3.8 6.7 2.2]
[5.4 3. 4.5 1.5]
[5.8 4. 1.2 0.2]
[6.4 2.8 5.6 2.2]
[6.1 3. 4.6 1.4]]
y_test [0 0 2 0 0 2 0 2 2 0 0 0 0 0 1 1 0 1 2 1 1 1 2 1 1 0 0 2 0 2 2 0 1 2 1 0 2
1]
X_train shape: (112, 4)
X_test shape: (38, 4)
# 使用scatter_matrix显示训练集与测试集。
import pandas as pd
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
# 创建一个scatter matrix,颜色值来自y_train
pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o', hist_kwds={'bins': 20}, s=60, alpha=.8)
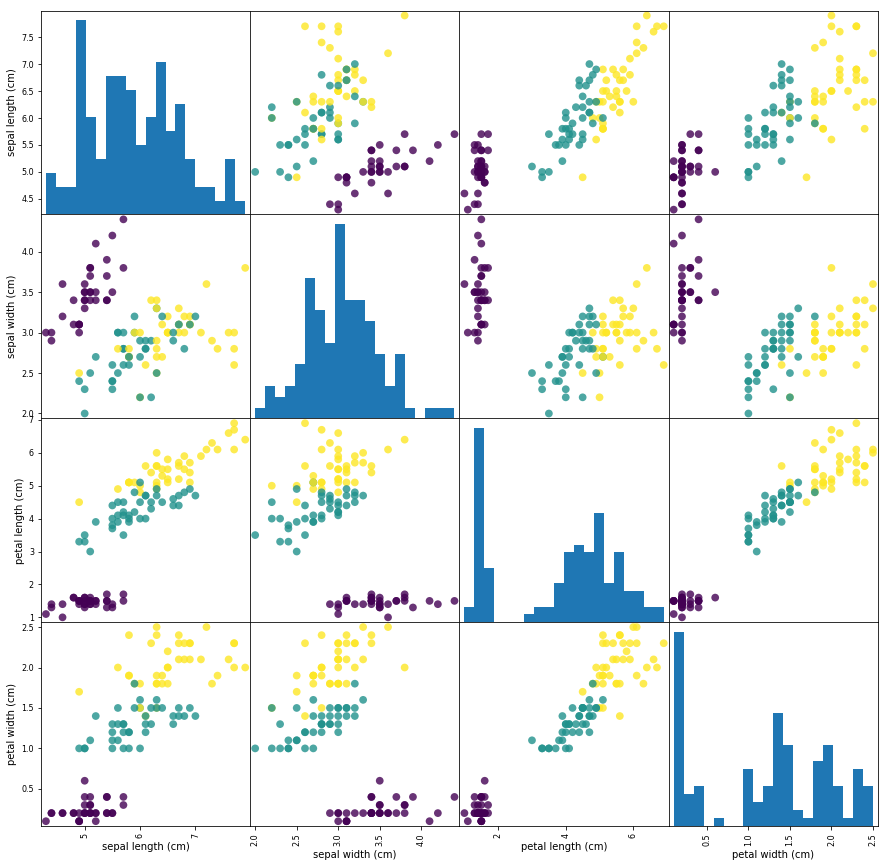
3.2 使用KNN对鸢尾花iris数据集进行分类。¶
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
#导入鸢尾花数据并查看数据特征
iris = datasets.load_iris()
print('数据集结构:',iris.data.shape)
# 获取属性
iris_X = iris.data
# 获取类别
iris_y = iris.target
# 划分成测试集和训练集
iris_train_X,iris_test_X,iris_train_y,iris_test_y=train_test_split(iris_X,iris_y,test_size=0.2, random_state=0)
#分类器初始化
knn = KNeighborsClassifier()
#对训练集进行训练
knn.fit(iris_train_X, iris_train_y)
#对测试集数据的鸢尾花类型进行预测
predict_result = knn.predict(iris_test_X)
print('测试集大小:',iris_test_X.shape)
print('真实结果:',iris_test_y)
print('预测结果:',predict_result)
#显示预测精确率
print('预测精确率:',knn.score(iris_test_X, iris_test_y))
数据集结构: (150, 4)
测试集大小: (30, 4)
真实结果: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0]
预测结果: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 2 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0]
预测精确率: 0.9666666666666667
3.3 使用KNN方法实现手写数字识别。¶
#coding=utf-8
import numpy as np
from os import listdir
def loadDataSet(): #加载数据集
#获取训练数据集
print("1.Loading trainSet...")
trainFileList = listdir('HWdigits/trainSet')
trainNum = len(trainFileList)
trainX = np.zeros((trainNum, 32*32))
trainY = []
for i in range(trainNum):
trainFile = trainFileList[i]
#将训练数据集向量化
trainX[i, :] = img2vector('HWdigits/trainSet/%s' % trainFile,32,32)
label = int(trainFile.split('_')[0]) #读取文件名的第一位作为标记
trainY.append(label)
#获取测试数据集
print("2.Loadng testSet...")
testFileList = listdir('HWdigits/testSet')
testNum = len(testFileList)
testX = np.zeros((testNum, 32*32))
testY = []
for i in range(testNum):
testFile = testFileList[i]
#将测试数据集向量化
testX[i, :] = img2vector('HWdigits/testSet/%s' % testFile,32,32)
label = int(testFile.split('_')[0]) #读取文件名的第一位作为标记
testY.append(label)
return trainX, trainY, testX, testY
def img2vector(filename,h,w): # 将32*32的文本转化为向量
imgVector = np.zeros((1, h * w))
fileIn = open(filename)
for row in range(h):
lineStr = fileIn.readline()
for col in range(w):
imgVector[0, row * 32 + col] = int(lineStr[col])
return imgVector
def myKNN(testDigit, trainX, trainY, k):
numSamples = trainX.shape[0] #shape[0]代表行,每行一个图片,得到样本个数
#1.计算欧式距离
diff=[]
for n in range(numSamples):
diff.append(testDigit-trainX[n]) #每个个体差
diff=np.array(diff) #转变为ndarray
#对差求平方和,然后取和的平方根
squaredDiff = diff ** 2
squaredDist = np.sum(squaredDiff, axis = 1)
distance = squaredDist ** 0.5
#2.按距离进行排序
sortedDistIndices = np.argsort(distance)
classCount = {} #存放各类别的个体数量
for i in range(k):
#3.按顺序读取标签
voteLabel = trainY[sortedDistIndices[i]]
#4.计算该标签次数
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
#5.查找出现次数最多的类别,作为分类结果
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
maxIndex = key
return maxIndex
train_x, train_y, test_x, test_y = loadDataSet()
numTestSamples = test_x.shape[0]
matchCount = 0
print("3.Find the most frequent label in k-nearest...")
print("4.Show the result...")
for i in range(numTestSamples):
predict = myKNN(test_x[i], train_x, train_y, 3)
print("result is: %d, real answer is: %d" % (predict,test_y[i]))
if predict == test_y[i]:
matchCount += 1
accuracy = float(matchCount) / numTestSamples
# 5.输出结果
print("5.Show the accuracy...")
print(" The total number of errors is: %d" % (numTestSamples-matchCount))
print(' The classify accuracy is: %.2f%%' % (accuracy * 100))
1.Loading trainSet...
2.Loadng testSet...
3.Find the most frequent label in k-nearest...
4.Show the result...
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 0, real answer is: 0
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 1, real answer is: 1
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 2, real answer is: 2
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 2, real answer is: 3
result is: 9, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 3, real answer is: 3
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 4, real answer is: 4
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 9, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 3, real answer is: 5
result is: 6, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 9, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 5, real answer is: 5
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 6, real answer is: 6
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 7, real answer is: 7
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 6, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 3, real answer is: 8
result is: 3, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 1, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 1, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 8, real answer is: 8
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
result is: 9, real answer is: 9
5.Show the accuracy...
The total number of errors is: 11
The classify accuracy is: 97.93%